
glm sas_glm sas class参考
非常感谢大家对glm sas问题集合的关注和提问。我会以全面和系统的方式回答每个问题,并为大家提供一些实用的建议和思路。
1.如何用SAS或SPSS求最小二乘均值
2.回归分析!!!!!!!!!!!!!
3.SPSS重复测量方差分析 三因素怎么做?
4.求英语达人帮忙
5.精算工作常用的精算软件有哪些?
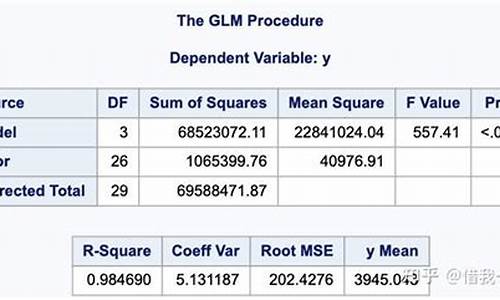
如何用SAS或SPSS求最小二乘均值
proc glm data=a;
class x7;
model y=x1-x7 x8;
lsmeans x7 /stderr at x8=1;
lsmeans x7/stderr at x8=0;
quit;
供参考,谢谢
回归分析!!!!!!!!!!!!!
根据简单效应的定义,做简单效应分析相当于对子数据集进行一元方差分析了!用SAS进行简单效应分析的程序如下:
proc sort data=anova_data;
by B;
run;
proc glm data=anova_data;
class A;
model dep_var=A;
means A / tukey;
means A;
by B;
run;
以上程序做3次一元方差分析(因素B有3个水平)。从另一个角度分析的程序如下:
proc sort data=anova_data;
by A;
run;
proc glm data=anova_data;
class B;
model dep_var=B;
means B / tukey;
means B;
by A;
run;
以上程序也是做3次一元方差分析(因素A有3个水平)。
SPSS重复测量方差分析 三因素怎么做?
用SAS作回归分析
SAS Institute (Shanghai) Co., Ltd.
(Regression Analysis)
变量的相关关系
散点图是直观地观察连续变化变量间相依
关系的重要工具
Insight, Air 或 Iris 看散点图阵
Insight: Analyze
Scatter plot(Y X)
或 Multivariate(Y's)
编程:proc gplot
Analyst: Graphs
Scatter plot
变量的相关关系
用直线描述
用曲线描述
可能有周期变化
无明显关系
相关系数(Correlation Coef.)
线性联系是描述变量联系中最简单和最常
用的一种(Y=a1x1+a2x2+b)
相关系数是描述两个变量间线性联系程度
的统计指标
相关系数的计算公式:
Insight Iris 看散点图与相关
相关系数(Correlation Coef.)
正相关:
一个变量数值
增加时另一个
变量也增加
负相关:
一个变量数值
增加时另一个
变量减少
相关系数(Correlation Coef.)
Insight: 置信椭圆
若变量有高度线性相关时相关系数接近 1
若变量有正相关时相关系数 > 0
若变量有负相关时相关系数 < 0
相关系数(Correlation Coef.)
强相关并不表示存在因果关系
弱相关并不表示变量间不存在关系
个别极端数据可能影响相关系数
相关系数的计算
SAS/INSIGHT
Analyze Multivariate (Y's)
Output Corr
在多变量分析窗中,由下拉菜单
Tables Corr
在散点图上加置信椭圆认识相关大小
Curves Confidence Ellipse
Prediction: . . .
相关系数的计算
Analyst
Statistics Descriptive Correlations
散点图与相关计算
Insight
散点图: bclass
Y: W, X: H, sex:颜色
age: 符号, 放大
散点图阵:cars
midprice,citympg,
egnsize,rpm,fueltnk,perform
旋转图:cars(iris)
perform, egnsize, idprice
相关系数:cars
midprice, citympg, hwympg, egnsize, rpm, perform
+ p-value
+置信椭圆
散点图与相关计算
Analyst与编程
Analyst:
相关计算:fitness
Oxygen, rstpulse, runpulse, runtime
+options: p-value
+plots 散点图+置信椭圆
编程:cars
p239 5变量相关
p241 nosimple noprob
with
相关系数的计算
Cor001 Class, Cor002 Fitness with, Cor003 Cars1 n不等
PROC CORR DATA=数据集名;
RUN;
PROC CORR DATA=数据集名;
var 变量名列;
with 变量名列;
partial 变量名列;
by 变量名列;
RUN;
相关与回归
相关分析量化连续变化变量间线性相
关的强度
回归分析确定一个连续变量与另一些
连续变量间的关系
回归(Regression)
描述一个变量与另一些变量间统计联系的关系式, Y=f(x1,x2,...,xm), 用于解释和预测.
确定回归:
确定变量:Y 与那些 x1, x2,. . , xm 有关
选择形式:Y 与 x1, x2,. . , xm 以什麽形式
相联系,即 f 的表示式
确定系数:确定 Y=a1x1+a2x1x2+a3x12+...
中的 ai
回归的简单线性模型
Yi = b0+b1xi+ei i=1,2,. . .,n
Yi: 因变量的第 i 次观测值
xi: 自变量的第 i 次观测值
b0,b1: 待估计的未知参数
ei: 余差(residual 相互独立,正态分布,零均值,同方差)
一般的:Yi=b0+b1x1i+b2x2i+. . .+bpxpi+ei
回归的简单线性模型
回归的简单线性模型
线性回归的拟合
最小二乘法估计(LSE)
SAS/INSIGHT
拟合线性回归
散点图,拟合:Analyze Fit(X,Y)
Noint: 强制截距为零
下拉菜单:
Tables: 方程,参数,Anova
预测值计算:在数据表独立变量栏键入数据
Curve:置信曲线 (ind., mean)
简单线性回归
Insight----Analyst
Insight: Cars:
Y:midprice, X:perform
解释输出结果
生成预测
加回归和预测置信带
shipment: Y:cost
noint
Analyst: Fitness:
Y:oxygen, X:runtime
+plot 散点图+置信带
shipment: noint
Y:cost, X: delay
回归的方差分解
总变异
回归阐明部分
回归未阐明部分
回归的方差分解
.
.
.
.
回归的方差分解
回归的假设检验
原假设:简单线性模型拟合数据不比基线
模型好
b1 = 0,
r = 0, |b1| 小,SS(Model) 小
备选假设:简单线性模型拟合数据比基线
模型好
b1 ^= 0,
r ^= 0, |b1| 不为零,SS(Model) 大
回归的方差分解
SS(Total)
= SS(error) + SS(Ind.-var) + SS(Const.)
预测值与置信限
回归分析计算
Analyst
Analyst: Statistics Regression
Simple . . .
回归分析计算
PROC REG DATA=数据集名;
MODEL 应变量=自变量;
RUN;
回归分析计算
P: p,加预测值和余差
PROC REG DATA=数据集名;
MODEL 应变量=自变量;
RUN;
PROC REG DATA=数据集名;
MODEL 应变量=自变量名列/ p cli clm
noprint
noint ;
id=变量名;
output=数据集名 关键统计量名=输出名. . .;
RUN;
回归分析计算
编程
P256 fitness oxy=runtime
p257 shipment noint
p258 fitness /p id
p259 计算预测值
p260 /cli
作图
p261 reg oxy*runtime
p262 /conf95 pred95
p264-1 gplot I=rl
p264-2 I=rlclm95
p265 /overlay
P266 I=rl0clm
p267 bclass w*h=sex
变换为线性 Diamond
回归分析计算
p180 最简
p182 id /p
p182_1 加入新自变量预测
p183 /clm cli
p183_1 加入新自变量预测
p184 /noprint; plot
p184_1 graphics
Noint: Reg033 散点,
Reg034 拟合
Reg039_1 拟合图,
Reg039_2 合一
Reg039_3 拟合+置信
变换为线性 Diamond
回归线作图
PROC REG DATA=数据集名 graphics noprint;
MODEL 应变量=自变量/p cli clm r;
PLOT y变量*x变量/选项;
symbol n c=颜色 v=值;
RUN;
利用proc reg 中的graphics选项和 plot语句
可以绘制与拟合数据有关散点图,回归线
和置信曲线,预测区间曲线
graphics 高分辨图,noprint 打印拟合数据
回归线作图
p185_1--4 散点,余差,CL散点,置信曲线
PROC REG DATA=数据集名 graphics noprint;
MODEL 应变量=自变量/p cli clm r;
PLOT y变量*x变量/选项;
symbol n c=颜色 v=值;
RUN;
y变量和x变量可以是应变量,
自变量和其它与回归分析有关
的变量:
p.(predicted) 预测值
r. (residual) 余差
U95., L95. 预测值置信限
U95M.,L95M.预测均值置信限
选项:
conf 95
作预测均值置信曲线
pred95
作预测值置信曲线
overlay
将语句中规定的图
迭置在一幅图上
AIC CP MSE SSE
在图上显示相应的统
计量
回归线作图
P
PROC GPLOT DATA=数据集;
PLOT 纵轴变量*横轴变量;
RUN;
PROC GPLOT DATA=数据集;
PLOT 纵轴变量*横轴变量 纵轴变量*横轴变量. . /
overlay;
symbol1 i=rlcli|rlclm 置信百分数 其它图形选项;
symbol2 i=rlcli|rlclm 置信百分数 其它图形选项;
RUN;
图形选项: c= value= cv= height= font= Line=
width= interpol=r ci=
回归线作图
用Proc Reg 作图
P185_1散点+拟合
P185_2 r. *runtime
P185_3 p. U95. . . .
P185_4 拟合及置信曲线
用 gplot:
p186 I, v, cv, h
p187 I, ci, w, l
p188 置信,clm cli /c
p189 overlay
Reg039_1--3 noint拟合与置信
p190 class 男女两条线
多变量线性模型
观测方程
Yi=b0+b1xi1+. . .+bpxip+ei, i=1,. . .,n
ei: 相互独立,正态分布,同方差,零均值
最小二乘估计:
归为b0 ,b1 ,. . .,bp 的一个线性方程组
多变量线性模型
多变量线性模型可同时研究 Y 与多个独立
变量 x1, x2,. . , xp 间的关系
对多变量模型进行解释和选择最优要比单
变量的模型复杂
在试验结果的解释,分析,预测等方面,
多变量线性模型是一个有力的工具.
一些变量间的非线性关系也可归为多变量
线性模型(例多项式关系)
p276 Cars2 剔除hwympg, fueltnk 看citympg.rpm
多变量线性模型
平方和分解
Options: P,CLM,CLI
多变量线性模型的检验
在多变量回归分析输出的回归参数的t -检验里,都是假定其它相依变量进入回
归的前提下检验该变量进入的显著性.
若模型中有两个变量有相关,在这一检验
中两者的显著性都可被隐蔽起来.所以,
这一检验结果必须小心分析.
删除变量时,必须逐个删除.并在删除每
个变量后,注意观测其它变量的p-值的
变化.
变量(模型)选择
在回归方程中,若遗漏了应加入的变量,
将使所有的回归系数估计量产生偏差;
若加入了不该加入的变量,将加大所有
的回归系数估计量的方差.
回归分析中变量的选择是要在独立变量中
找出合适的子集,用以描述模型和进行
预报.
常用的有:全部可能回归方法(更多的侯选模型)和逐步回归法(节省计算资源).
变量选择准则
(逐步回归)
逐步回归方式挑选有关的选项:
NONE:全部进入,不加选择
FORWARD: 逐个加入
BACKWARD: 全部加入后逐个剔除
STEPWISE: 边进边出
MAXR:逐个加入和对换,使R2增加最大
MINR: 逐个加入和对换,使R2增加最小
变量选择准则
(逐步回归)
MAXR:开始加入使R2增加最大的变量
以后每一步选择模型内外变量进行对换,
选择R2增加最大的对换
选择加入一个使R2增加最大的新变量
MAXR:开始加入使R2增加最小的变量
以后每一步选择模型内外变量进行对换,
选择R2增加最小的对换
选择加入一个使R2增加最小的新变量
变量选择准则
(全部回归)
回归分析计算
Analyst: Statistics Regression
Linear . .
变量选择: Model
多变量回归分析
Insight: Fitness
Y:midprice, X:其它7个数值变量
+ (copy) delete hwympg
dst.paper 多项式回归
Y:strength amount**4
+I type tests
Analyst: Fitness
Y:Oxygen, X: age, maxp, rstp.,runp.,runtime weight
+ Model method f.
回归分析计算--变量选择
PROC REG DATA=数据集名;
MODEL 应变量=自变量名列/p cli clm r
noprint
selection= backward |forward| stepwise
rsquare |adjrsq|cp
slentry=0.50 slstay=0.10
best=个数 aic sbc rmse include=n ;
id=变量名;
output=数据集名 关键统计量名=输出名. . .;
RUN;
P
多变量回归分析
变量选择:Dst: Fitness
p282 oxy=age weight rstp maxp runp runt
p284 delete rstp
p285 /selection=stepwise
p288 /sel.= rsquare b
p289-1 /sel.=rsq. b
best=2
p289-2 /sel=cp adjrsq
多项回归:paper
p290 streng.=amount**3
p291 glm 看检验4次
--------------------------
p191 全进; p192 delete
p193 backward forward (slstay=slentry=0.1)
p195 stepwize
p198 rsquare adjrsq cp
p199 best=2
拟合多项式模型
多项式函数是非线性函数中较为简单的一
类,它也可通过多元线性回归来拟合
Y=b0+b1x+b2x2+b3x3+. . .
引入新变量 xi = xi
Y=b0+b1x1+b2x2+b3x3+. . .
INSIGHT提供简便的方法拟合多项式并显
示图形
proc reg和proc glm都可用于拟合多项式
Insight dst.paper, Reg084_1--2 拟合及图 看SS1
I 型平方和
I型(Sequential)平方和记录回归变量逐个
进入回归时,模型平方和的增加量
I 型平方和
I型平方和可转化为F 统计量,用以对回归模
型 Y=b0+b1x1+b2x2+b3x3+e 作如下的检验:
两种平方和: SS1,SS2
两种平方和: SS1,SS2
因此,若进入回归的变量有一定的优先次序(如对多项式,线性项先二次项,二次项先于三次项等),应该用 I 型平方和及相应的F 统计量.若平等地考虑各个变量是否进入回归,则可用 II 型平方和及其相应的F 统计量.
两种平方和: SS1,SS2
Insight
Insight: Tables Type I(III) Tests
两种平方和: SS1,SS2
多项式:Reg084_3 拟合 SS1 SS2
Analyst: Statistics Regression Linear . .
Statistics Statistics SS1 SS2
两种平方和: SS1,SS2
PROC REG DATA=数据集名;
MODEL 因变量名列=自变量名列
OUTPUT OUT= 数据集名;
RUN;
PROC GLM
PROC GLM用最小二乘法拟合一般的线性
模型,包括回归分析,方差分析等
它与proc reg一样提供方差分析,参数估
计检验和两类平方和
它提供关于两类平方和的检验
拟合多项式回归时不必预先生成变量的高
次项
它不提供回归诊断的信息
PROC GLM
多项式: Reg094,084_4拟合. 图reg097, reg098. 综合:fish例
PROC GLM DATA=数据集名;
CLASS 变量名列;
MODEL 因变量名列=自变量名列
OUTPUT OUT= 数据集名;
RUN;
变量*变量*... 变量|变量|...
FIT(X,Y)
回归诊断
例外值(outliers)或异常作用点的检查
从已拟合回归的数据中分析线性模型的假定是否被破坏:
应变量的均值是否是独立变量的线性函数,是否
需要对变量进行变换或拟合曲线回归
余差(residuals)是否同方差,不相关,正态分布
独立变量间是否存在线性关系(仅多元有)
考察余差散点图是进行回归诊断的必要步骤
回归诊断
回归诊断
Ascombe's 例
Ascombe's例
Insight: dst.ascombe
reg228编程作4图合一
reg228,1-4分别作图
reg222,1-3编程分析
A:x1,y1, I:x1,y2,
O:x1,y3, H:x2,y4
回归诊断
回归分析的余差值是回归诊断的重要工具
利用余差可以考察余差和预测值的散点图
也可以检验余差分布的正态性
回归诊断
模型合适
应改曲线模型
不等方差
观测值不独立
回归诊断
生成余差
在INSIGHT中拟合回归后在数据表中回自动
生成预测值,余差值和余差-预测散点图
回归诊断
生成余差
Analyst: Statistics Regression Linear . . .
Predictions预测值,余差值
回归诊断
Insight: Cars
Var Std res., 找绝对值超过2者
var Cook's D 超过 4/92=0.04348
var Dffits 超过 2sqrt((k+1)/n)=0.58977
参数估计表中看vif
output+collinearity…看条件指数与方差比例
Analyst: Cars
+p.,r.,student to dst
+plot: std.*p.
+cookd > 0.0435,
dffits > 58977
+statisitcs tests
Collinearity, vif
回归诊断
生成余差
在PROC REG的model语句加上选项 p,就会
输出预测值和相应的余差
PROC REG DATA=数据集名 graphics ;
MODEL 应变量=自变量/p;
PLOT y变量*x变量/选项;
symbol n c=颜色 v=值;
RUN;
利用plot语句 plot r.*p. ; 就可得到余差-
预测散点图
回归诊断
识别异常观测值
回归诊断
识别异常观测值
在PROC REG的model语句加上选项 r,就会
输出与预测值和余差有关的一些统计量.他
们可用于识别异常数据(outlier)及其影响
PROC REG DATA=数据集名 ;
MODEL 应变量=自变量/r;
RUN;
Predict Value 预测值
Std Err Predict 预测值标准差
Residual 余差
Std Err Predict 余差标准差
Student Residual student化的余差
-2 -1 0 1 2 余差显著性图
Cook's D Cook's D统计量
与余差有关的统计量
回归诊断
余差分布正态性
有了余差的数据,就可对其运用图形方法
或正式的分布正态性的检验
在INSIGHT中可直接对数据表中的预测余
差变量进行分析
在PROC REG可利用下列语句用图形分析
余差分布正态性
PROC REG DATA=数据集名 graphics ;
MODEL 应变量=自变量;
PLOT nqq.*student.(nqq.*r.);
RUN;
回归诊断
识别有影响的观测
回归诊断
识别有影响的观测
Cook D统计量度量一个观测从分析中剔除
时参数估计值的变化
对一个观测值其 Cook D 统计量的值超
过 4/n 时(n为样本容量),这个观测存在
反常效应
SAS/INSIGHT 在下拉菜单选
Var Cook's D
回归诊断
识别有影响的观测
Dffitsi 度量第i 个观测对预测值的影响
第i个观测的预测值
用排除第i个观测的回归对第i个观测的预测值
第i个观测的预测值的标准差
p 为模型中参数的个数, n 为样本容量
SAS/INSIGHT 在下拉菜单选Var Dffits
回归诊断
识别有影响的观测
Analyst: Statistics Regression Linear . . .
Save Data
回归诊断
识别有影响的观测
Proc REG 的 Model语句加选项 r 可获得
Cook D 统计量
Proc REG 的 Model语句加选项 influence
可获得 Dffits 等反映观测值影响的统计量
PROC REG DATA=数据集名 ;
MODEL 应变量=自变量/r influence;
RUN;
回归诊断
编程
Dst.cars
p311 /r
p312 output+ p. r. student.
p313 plot student.*p.
P314-1 /influence
p314-2 output cookd dffits
p315 /collin vif
选项 influence 生成的统计量
R022 Influence
回归诊断
识别有影响的观测
偏杠杆图是使有影响观测可视化的方法
偏杠杆图是两个回归的散点图
例如对变量 xr 的偏杠杆图:
纵轴是Y关于除xr以外所有x的回归的余差
横轴是xr关于所有x的回归的余差
有影响观测通常分离与其它数据点或在某
一轴上有极端数值
偏杠杆图还可识别要加入哪些变量的高次项
回归诊断
识别有影响的观测
SAS/INSIGHT 在下拉菜单选
GraphsPartial Leverage
Proc REG 的 Model语句加选项partial 可
获得杠杆图(低分辨)
PROC REG DATA=数据集名 ;
MODEL 应变量=自变量/partial;
RUN;
回归诊断
识别有影响的观测
如何处理有影响的观测
复验数据,确认并无数据输入错误发生
若数据是有效的,模型可能不合适.拟
合此数据可能需要使用高阶模型
也可能数据是反常的
一般,不剔除数据.某些有影响的观测提
供重要的信息.要剔除数据,应给出必
要的描述和说明
回归诊断
共线性诊断
共线性(collinearity, multicollinearity)问题是指
独立变量间存在线性关系
变量间的线性关系会隐蔽变量的显著性
也会增加参数估计的方差
产生不稳定的模型
只有拟合多元回归才会发生这一问题
共线性的诊断可使用方差膨胀因子,条件指数和方差比例
回归诊断
共线性诊断-VIF
方差膨胀因子(VIF)是对由于共线性而引起的参数估计量的方差增加的一个相对度
量
dst.cars2
Rr2 是Xr关于模型中其它独立变量回归的R2
一般采用 VIF >10 表明存在共线性问题
INSIGHT在拟合回归时自动生成VIF
Proc REG 的Model语句加选项 VIF
回归诊断
共线性诊断-条件指数和方差比例
条件指数(condition index)和方差比例
(variance proportion)联合使用可确认存在
线性关系的变量组
条件指数(hi=(lmax/li)1/2)
在10-30间为弱相关
在30-100间为中度相关
大于100表明有强相关
大的条件指数伴随方差比例> 0.5 可确认有
共线性的独立变量子集
INSIGHT在下拉菜单中选
TablesCollonearity Diagnostics
Proc REG: Model语句
加选项collin 或 collinoint
回归分析计算
PROC REG DATA=数据集名 graphics noprint;
MODEL 应变量=自变量名列/p cli clm r vif
influence partial collin collinoint;
PLOT y变量*x变量/选项 . . .;
id=变量名;
output=数据集名 关键统计量名=输出名. . .;
RUN;
作图变量:r., student., nqq., ...
回归诊断
例外值(outliers)或异常作用点的检查
从已拟合回归的数据中分析线性模型的假定是否被破坏:
应变量的均值是否是独立变量的线性函数,是否
需要对变量进行变换或拟合曲线回归
余差(residuals)是否同方差,不相关,正态分布
独立变量间是否存在线性关系(仅多元有)
考察余差散点图是进行回归诊断的必要步骤
Reg228,Reg228_1-228_4 Ascombe's 例
Lack -of -Fit 检验
若对于独立变量 有应变量的重复观测值
则可将线性预测误差平方和分解为纯误差
平方和与Lack-of-fit平方和,用以检验
拟合线性回归是否合适
Lack -of -Fit 检验
求英语达人帮忙
从SAS板块可以下到余松林老师所著的《重复测量资料分析方法与SAS程序》的电子书,里面介绍了用SAS的mixed模块可以处理不等距重复测量设计资料,并附例题,建议去看看。
按照我的理解,SPSS的GLM菜单下的repeated measure命令是不能处理不等距重复测量资料的。
其实不用那么麻烦的,你先定义几个变量,如组别,在Variable View栏中设置组别变量1,2,3...5,然后返回Data View在组别中输入1或2或...或5即可。
建议你看看《SPPS在统计分析中的应用》第五章统计推断例题中的例题结构即可。
SPSS菜单如下:
Analyze->General Linear Model->Univariate
不过试验次数少,只能进行主效应分析,不能进行交互效应分析,所以还要调整模型,在Model里面。
总之试验次数不够,还要再增加次数。
精算工作常用的精算软件有哪些?
大于或等于0.0001,原假设不能成为比任何已经选中的显著性水准还高的假设。
方法报告(第20行表3.8)使样品被打印出来, LSMEANS语句(21行)要求印出平均值,?+?τi。在单向方差分析模型,这些都是相同的。从两份报告得出的输出信息显示于表格3.10。
一个对观察次数的计算需要更进一步的实验,而这个实验不能用广义线性模型来完成。从中间实验得出的均方误差的值可以通过一个方差分析表来计算。然后样本大小的计算需要自己手工完成,就像第3.6章那样。
1.假设你正在做一个拥有处理因素而且没有阻断因素的实验,但这个处理因素有四个级别。假设对所需观察次数的计算已经用r1=2r=3r=r4=45表型给出了,把20个实验单元随机分成4个处理层次,这样每个处理组都分到5个单元。
2.假设你正在运行一个拥有有3个层次的处理因素而且没有阻断因素的实验,已经知道 r1=3, r2 =r3=5,随机把13个实验单元分成3个处理组,这样第一个处理组就分到3个单元,其他两组各分到5个单元。
3.假设你正在做一个拥有3个处理因素的实验,第一个因素有2个层次,其他两个各拥有3个层次。写出18个处理组合的编码形式。把36个单元随机分给这18个处理组合,这样每个处理组合都分到2个单元。
4.对于单向方差分析模型(3,3,1),在第36页。用sas软件处理的标准方程的解答是 τ1=yi? y?(i0 1, . . . , v)和?=y?。
(a).t1是有限的吗?并说明理由。
(b)计算t1-t2相对于以上解答的最小平方的估量值的期望值,t1-t2是有限吗?并作说明。
5.考虑一个完全随机的设计,此设计带有的观察值分在三个处理层次上(编号1,2,3)。根据单向方差分析模型(3,3,1),第36页,确定一下哪些是有限的。对于有限的项,说出最小平方的估量值。
(a) τ1+ τ2? 2τ3
(b)? + τ3.
(c) τ1? τ2? τ3.
(d)? + (τ1+ τ2+ τ3)/3.
我的翻译肯定不是专业水准,,,我没学着专业,只是喜欢英语,,,,,
其实最常用的是Excel,而且Excel能够解决你面临的几乎全部问题,只要你水平够。但是,在很多场景下Excel的效率并不高,比如大规模的数据管理。所以精算师往往也需要会用一些简单的数据库工具,最常见的就是Access。FoxPro, FoxBase甚至是dBaseIII现在已经很不常用了。另外,Excel作为模型管理工具的能力也很弱,版本控制也很困难。专用的精算软件在这个方面就很有优势。同时,专用精算软件在运算效率上也比Excel公式计算和VBA非编译计算要高很多,更适合大型复杂模型和多经济情景的分布式计算。现在流行的专用精算建模软件有如下几款:1. SunGuard的Prophet:这款软件在亚太地区很流行,国内几乎所有的寿险公司都在用这一系列的软件,除了中国人寿。
2. Towers Watson的MoSes:作为同样是用先知名字命名的软件,在国内主要有中国人寿和太平洋保险在使用这款软件。其实这款软件在其发源地美国并不成功,原因很多,这里就暂不详述了。
3. Tillinghast的TAS系列:这款软件早年间在美国非常成功,使用起来也很方便友好,但是公司在版本升级到10.0时步子迈得太大,有点扯到蛋,而旧版本9.x系列底层也的确太陈旧,所以很快在美国遭到了用户的抛弃。尤其,在Towers Perrin与Watson Wyatt合并后,公司对于TAS和MoSes的定位有点摇摆不定,现在也基本属于被淘汰的地位。缺点是可编程性较弱,多数情况下只能通过修改模型参数和配置达到改变模型的效果。虽说有CalcFlex作为补充,但由于其C++的特性,导致对于普通精算师来说上手门槛较高,代码管理和debug都比较困难。
4. Milliman的MG-ALFA:这款软件在美国日本市场占有率很高,功能也非常强大。过去十年间版本迭代很快,精算逻辑部分采用的是简单代码,不需要使用指针、循环等较难的代码技能,debug界面(6.3版本之后)也非常友好。而在UDF里又可以进行完整的C++编程,又可以实现非常复杂的高级功能,深受精算师用户的喜爱。但是这款软件在国内并不流行,只有个别小公司在使用。而2013年Milliman决定在大陆放弃推广这款软件,转而支持Prophet,实在比较可惜。
5. GGY的AXIS:这款软件在加拿大比较流行,也适合当地的监管环境。只是这款软件基本是个黑盒子,大部分定制化的功能都需要通过GGY来进行编程,灵活性有限。
好了,今天关于glm sas就到这里了。希望大家对glm sas有更深入的了解,同时也希望这个话题glm sas的解答可以帮助到大家。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。











